Futuristic Fantasy Adventure Art
4
--sref 2314938599 Copy sref code
2314938599
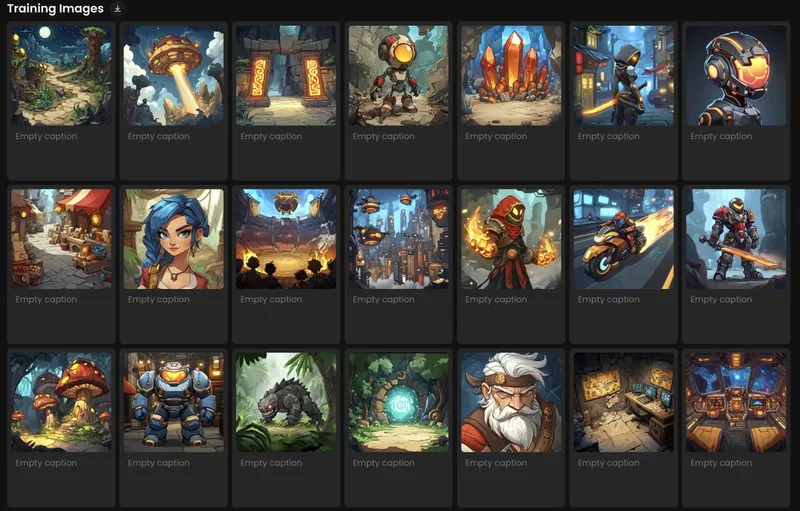
Copy sref codeI trained it on Scenario using 27 images initially made on Midjourney with --sref 2314938599 (very grateful to @steelparsley for this code )
Surprisingly... this model did well without ANY captions (I also tried with captioning, with lesser quality outputs)
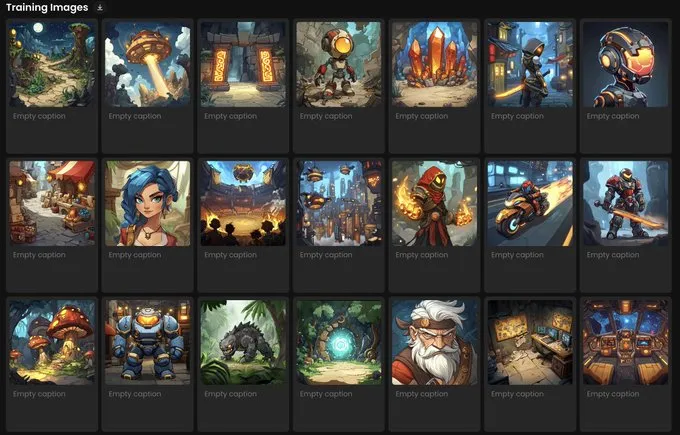
I trained it on Scenario using 27 images initially made on Midjourney with --sref 2314938599 (very grateful to @steelparsley for this code )
Surprisingly... this model did well without ANY captions (I also tried with captioning, with lesser quality outputs)